Бесплатный API для нейросетей и автоматический агрегатор новостей в n8n

 346
346
Хотите тестировать свои проекты с LLM, не тратя деньги на токены? В этой статье разберём, как получить бесплатный доступ к нейросетям через сервис immers.cloud и создать полезную автоматизацию — агрегатор новостей, который сам собирает информацию из разных источников, обрабатывает её с помощью ИИ и публикует готовые посты в Telegram.
Что такое публичные endpoint'ы и зачем они нужны
Когда вы разрабатываете продукт с использованием нейросетей, на этапе тестирования и отладки приходится делать множество запросов к API. Каждый такой запрос стоит денег — вы платите за токены. Пока продукт не готов к продакшену, эти расходы могут быть неоправданными.
Публичные endpoint'ы решают эту проблему. Это бесплатные точки доступа к нейросетям, которые предоставляют некоторые сервисы. Вы можете использовать их для:
- тестирования своих идей;
- отладки интеграций;
- обучения и экспериментов;
- создания прототипов.
Один из таких сервисов — immers.cloud, который предоставляет бесплатный доступ к нескольким популярным моделям.
Обзор immers.cloud
Какие модели доступны бесплатно
На странице https://immers.cloud/ai/model представлен каталог моделей. Чтобы найти бесплатные, используйте сортировку и обратите внимание на тег «Можно попробовать» — он означает, что у модели есть публичный endpoint.
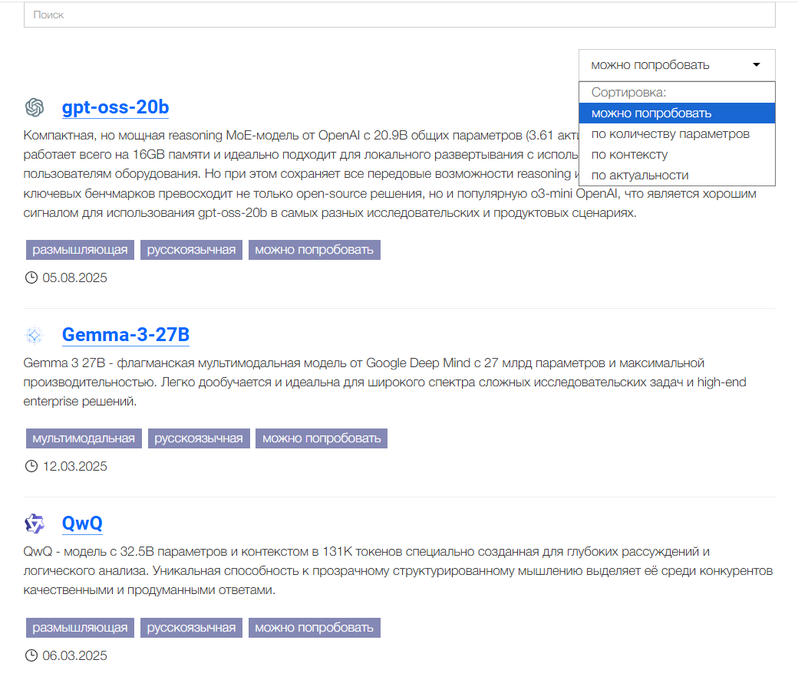
На момент написания статьи бесплатно доступны:
- Qwen3-30B
- GPT-USS-20B
- Qwen3-235B
- Gemma
- QVQ
Разработчики обещают расширять список, добавляя в том числе модели для генерации изображений.
Как изучить модель перед использованием
Нажав на любую модель в каталоге, вы увидите подробную информацию:
- дату анонса;
- количество параметров;
- размер контекстного окна;
- количество слоёв;
- потребление видеопамяти;
- тип квантования.
Также можно перейти на страницу разработчика модели и посмотреть другие его проекты.
Преимущество каталога immers.cloud в том, что команда сервиса уже отобрала и протестировала модели. Вам не нужно самостоятельно разбираться во всех разновидностях — например, у одной только Qwen3 их множество. Если хотите глубже погрузиться в тему выбора моделей, рекомендую посмотреть видео о поиске нейросетей на Hugging Face.
Информация о публичном endpoint'е
На странице модели с тегом «Можно попробовать» отображается:
- размер контекста;
- тип доступа (публичный);
- на каком оборудовании запущена модель (например, 3× RTX 4090);
- текущий статус (доступна/недоступна).
Здесь же есть кнопка «Чат» — можно сразу пообщаться с моделью и оценить качество её ответов.
Ссылка на Hugging Face позволяет изучить оригинальную документацию модели.
Примеры использования API
На странице модели приведены готовые примеры запросов для разных инструментов:
curl https://chat.immers.cloud/v1/endpoints/gpt-oss-20b/generate/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer USER_API_KEY" \
-d '{"model": "gpt-oss-20b", "messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Say this is a test"}
], "temperature": 0, "max_tokens": 150}'
PowerShell — аналогичная структура запроса.
Python с библиотекой OpenAI:
#!pip install OpenAI --upgrade
from openai import OpenAI
client = OpenAI(
api_key="USER_API_KEY",
base_url="https://chat.immers.cloud/v1/endpoints/gpt-oss-20b/generate/",
)
chat_response = client.chat.completions.create(
model="gpt-oss-20b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Say this is a test"},
]
)
print(chat_response.choices[0].message.content)
Обратите внимание: для Python URL заканчивается на /generate, а не на /generate/chat/completions.
Как получить API-ключ
Для работы с публичными endpoint'ами нужен токен авторизации.
Шаг 1. Зарегистрируйтесь на immers.cloud.
Шаг 2. Перейдите на страницу управления токенами.
Шаг 3. Нажмите «Создать».
Шаг 4. При желании укажите срок действия токена (можно оставить значения по умолчанию).
Шаг 5. Нажмите «Сохранить».
Шаг 6. Скопируйте выданный токен — он понадобится для всех запросов к API.
Практика: создаём агрегатор новостей в n8n
Теперь применим полученные знания на практике. Создадим workflow, который:
- Собирает новости из нескольких RSS-источников.
- Фильтрует только свежие публикации (за последние 24 часа).
- Отправляет их в LLM для обработки и форматирования.
- Публикует готовый пост в Telegram-канал.
Что такое n8n
n8n — это инструмент для автоматизации с визуальным интерфейсом. Вы соединяете «ноды» (узлы) в цепочку, и каждая нода выполняет определённое действие: делает HTTP-запрос, обрабатывает данные, отправляет сообщение и так далее. n8n можно развернуть на своём сервере или использовать облачную версию.
Общая схема workflow
Наш workflow состоит из следующих этапов:
- Триггер по расписанию — запуск каждый день в 10:00.
- Получение текущей даты — LLM не знают, какой сегодня день.
- Три HTTP-запроса — получение RSS-лент из разных источников.
- Объединение данных — слияние трёх потоков в один.
- Обработка кодом — парсинг XML, фильтрация по дате.
- Агрегация — преобразование в JSON для LLM.
- Запрос к LLM — генерация текста поста.
- Отправка в Telegram — публикация результата.
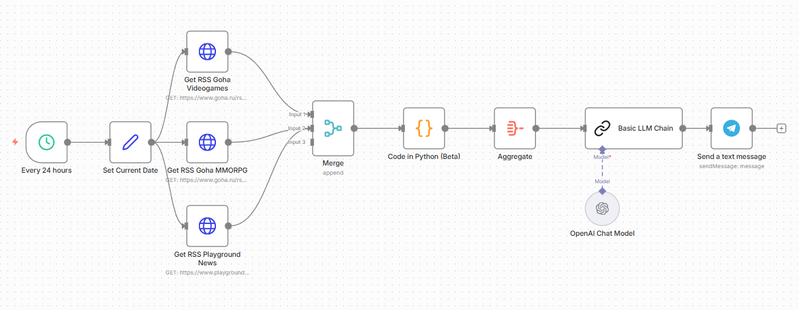
Настройка каждой ноды
Триггер по расписанию (Schedule Trigger)
Эта нода запускает workflow автоматически. Настройки:
- Тип: ежедневно
- Время: 10:00
Получение текущей даты (Date & Time)
LLM не имеют доступа к актуальной дате, поэтому её нужно передавать явно. Нода формирует строку с текущей датой, которую мы позже передадим в промпт.
HTTP-запросы для RSS
Создаём три ноды HTTP Request — по одной для каждого источника новостей. Настройки:
- Метод: GET
- URL: адрес RSS-ленты (например, лента новостей об играх)
RSS возвращает данные в формате XML.
Объединение данных (Merge)
Нода Merge объединяет результаты трёх запросов. Используем режим Append — данные просто добавляются друг к другу.
Обработка кодом (Code)
n8n поддерживает Python (в бета-версии). Этот код делает следующее:
- Парсит XML из RSS.
- Извлекает нужные поля: заголовок, ссылку, краткое описание, дату публикации.
- Фильтрует новости — оставляет только те, что опубликованы за последние 24 часа.
На выходе получаем список объектов:
import xml.etree.ElementTree as ET
from datetime import datetime, timedelta, timezone
from email.utils import parsedate_to_datetime
import re
import html
# Список для всех найденных новостей со всех лент
all_news_items = []
# Настройки времени
now = datetime.now(timezone.utc)
threshold = now - timedelta(hours=24)
# === ФУНКЦИЯ ОЧИСТКИ ===
def clean_html(raw_html):
if not raw_html:
return ""
# а) Удаляем HTML теги
clean_text = re.sub(r'<[^>]+>', ' ', raw_html)
# б) Удаляем мусор
clean_text = clean_text.replace('Читать дальше →', '').replace('Читать дальше', '')
# в) Спецсимволы
clean_text = html.unescape(clean_text)
# г) Пробелы
return " ".join(clean_text.split())
# =======================
# Проходимся по ВСЕМ входящим элементам (RSS-лентам)
inputs = _input.all()
for input_item in inputs:
# Получаем XML данные из текущего элемента
# Проверяем, есть ли ключ 'data', так как структура может отличаться
try:
input_xml = input_item['json'].get('data')
if not input_xml:
continue # Пропускаем, если данных нет
# Парсим XML
try:
root = ET.fromstring(input_xml)
except ET.ParseError:
print("Ошибка парсинга XML")
continue
# Ищем новости в текущей ленте
# Поддержка разных путей (иногда item лежит прямо в root, иногда в channel)
items = root.findall('./channel/item')
if not items:
items = root.findall('.//item')
for item in items:
pub_date_str = item.find('pubDate').text
if pub_date_str:
try:
pub_date_obj = parsedate_to_datetime(pub_date_str)
# Фильтр по времени
if pub_date_obj > threshold:
def get_text(tag):
el = item.find(tag)
return el.text if el is not None else None
raw_description = get_text('description')
post = {
"title": get_text('title'),
"link": get_text('link'),
"summary": clean_html(raw_description),
"pubDate": pub_date_obj.isoformat()
}
# Добавляем в общий список в формате n8n
all_news_items.append({'json': post})
except Exception as e:
print(f"Ошибка обработки даты: {e}")
continue
except Exception as e:
print(f"Ошибка обработки элемента: {e}")
continue
return all_news_items
Агрегация (Aggregate)
Собираем все отфильтрованные новости в один JSON-объект для передачи в LLM.
Запрос к LLM (Basic LLM Chain)
Здесь происходит магия — нейросеть превращает сырые данные в читаемый пост.
Системный промпт:
Сделай пост в телеграм о последних новостях компьютерных игр, на сегодня.
Вот пример:
Игровые новости на 13.10.2025 [тут эмодзи]
Metaphor: ReFantazio Atlus отметила год с выхода игры, но вместо ожидаемых фанатами анонсов или
обновлений просто запустила продажу нового цифрового издания.
Многие разочаровались, ждали чего-то вроде DLC или продолжения, а получили чисто коммерческий ход.
Зато это напомнило, насколько игра крутая в своей фэнтезийной RPG-механике с социальными
элементами, так что если не играли, самое время наверстать.
Пользовательский промпт включает:
- инструкции по формату вывода;
- пример желаемого результата;
- сегодняшнюю дату;
- список новостей в JSON.
Поскольку у нас три источника (MMORPG, компьютерные игры, общие игровые новости), LLM может сгенерировать несколько постов, группируя новости по темам.
Проанализируй этот список новостей игр (собранных из разных источников) за последние 24 часа.
Выбери самые важные и интересные (исключи дубликаты, если одна новость есть на разных сайтах).
Напиши ОДИН пост-дайджест для Telegram в легком стиле.
Используй эмодзи.
Сегодня дата {{ $json.data[0].pubDate }}
Формат каждой новости:
- Заголовок
- Краткая суть (3-4 предложения)
Вот данные:
{{ $json.data.map(item => `Заголовок: ${item.title}\nСуть: ${item.summary}`).join("\n---\n") }}
Отправка в Telegram
Нода Telegram отправляет сгенерированный текст в канал. Для работы нужен Telegram-бот с правами администратора в канале.
Подключение immers.cloud к n8n
В ноде Basic LLM Chain нужно настроить credentials для immers.cloud:
Base URL:
https://chat.immers.cloud/v1/endpoints/[название-модели]/generate/
API Key: токен, полученный на странице управления токенами.
После настройки в списке моделей появится доступная публичная модель.
Результат работы
После запуска workflow в Telegram-канал приходит отформатированный пост с игровыми новостями за сутки. Вся информация собрана из трёх источников, обработана нейросетью и готова к публикации — без ручного участия.
Идеи для расширения
Созданный workflow — это базовый пример. Вот как его можно развить.
Использование RSS-агрегаторов
Вместо прямых запросов к RSS можно использовать self-hosted агрегаторы:
- FreshRSS
- Miniflux
- Tiny Tiny RSS
Эти инструменты быстро разворачиваются в Docker, самостоятельно собирают новости по расписанию и хранят их в базе данных. Преимущества:
- данные всегда актуальны;
- можно добавить десятки источников;
- поддержка webhook'ов для мгновенной реакции на новые публикации.
Увеличение частоты обновлений
Вместо одного запуска в день можно настроить проверку каждый час или даже реагировать на webhook от RSS-агрегатора. Так вы будете получать новости практически в реальном времени.
Другие каналы доставки
Помимо Telegram можно отправлять сводки:
- на email;
- в Slack или Discord;
- в Notion или другие базы знаний.
Другие тематики
Этот же принцип работает для любой области:
- новости о нейросетях и AI;
- обновления фреймворков и библиотек;
- новости индустрии;
- мониторинг упоминаний бренда.
Заключение
Мы разобрали, как использовать бесплатные публичные endpoint'ы immers.cloud для работы с нейросетями без затрат на токены. Это отличное решение для тестирования, обучения и создания прототипов.
На практическом примере создали полезную автоматизацию в n8n — агрегатор новостей с обработкой через LLM и публикацией в Telegram. Такой workflow экономит время и позволяет всегда быть в курсе событий.
Подписывайтесь на наш Telegram канал, чтобы оставаться курсе последних событий в мире AI.
Видео на тему "Бесплатный API для нейросетей и автоматический агрегатор новостей в n8n"
YouTube
RuTube
Авторизуйтесь, чтобы оставить комментарий.
Нет комментариев.